
全球20%互联网“瘫痪”3小时!Cloudflare史诗级宕机,ChatGPT、···
在许多人还以为只是自己 Wi-Fi 出问题时,一场席卷全球的网络大面积故障,悄然让半个互联网陷入了罕见的混乱:
X(原 Twitter)打不开、ChatGPT 无法响应、连监控宕机的 Downdetector 自己都挂了……而这场风暴的中心,正是那个几乎包裹了全球五分之一互联网的
基础设施服务商:Cloudflare。

一觉醒来,互联网“碎了一地”:从社交媒体到游戏服务器全面崩溃
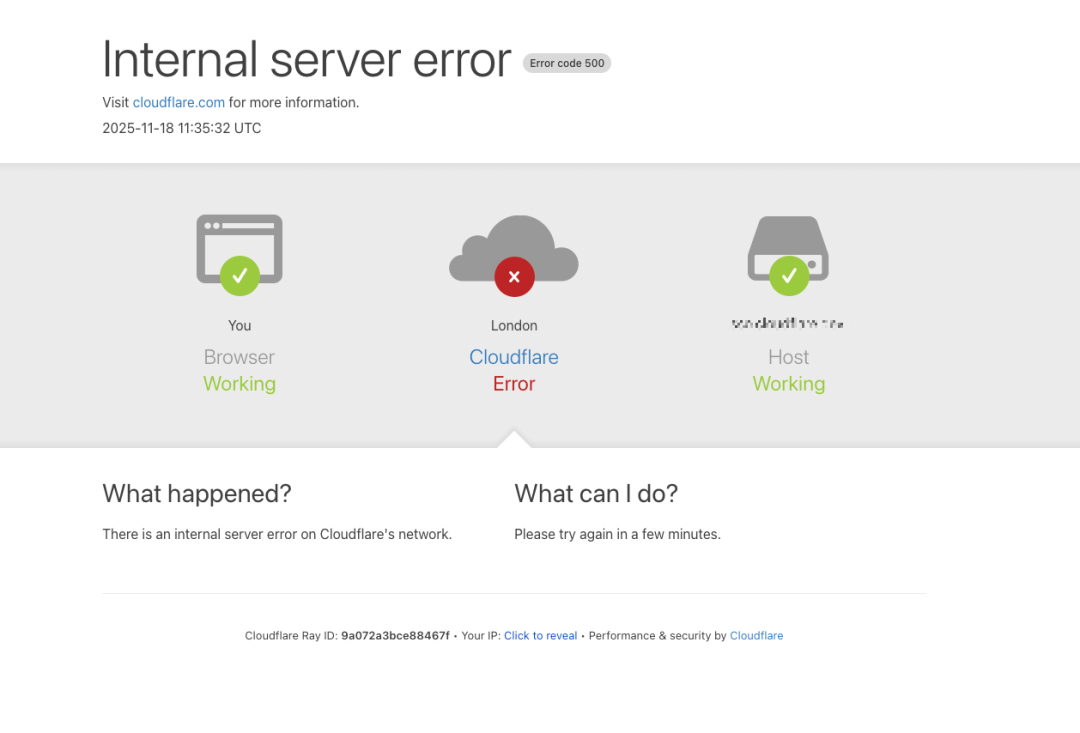
根据媒体报道,Cloudflare 故障在美东时间早上 6:20(北京时间 19:20)左右开始,最先爆出来的是大量应用访问延迟、白屏、无法登录等问题。
受影响的名单长到令人咋舌——不仅有 X、ChatGPT,这场崩溃还几乎跨越了社交网络、生产力工具、流媒体、在线游戏、交通服务等所有类别:
● X:报错信息显示“内部服务器错误源于 Cloudflare 的异常”;
● ChatGPT:弹出提示“请解除对 cloudflare.com challenge 的拦截后继续访问”;
● Canva(在线设计工具)、Indeed(招聘平台)、Uber(打车软件)、Spotify(音乐播放平台)均出现访问异常;
● 《英雄联盟》服务器出现连接问题;
● Archive of Our Own(AO3)短暂无法访问;
● 大量媒体网站也全部挂掉,包括但不限于Axios、The Information和Politico。
甚至,连人们用来确认网站是否挂掉的 Downdetector 本身都无法正常加载——这无疑是本次事件最为戏剧性的一幕。
数不清的用户在社交媒体上不断发出抱怨,有人甚至调侃:“这已经不只是网站挂了,是我的一天也跟着宕机了。”

为什么 Cloudflare 一挂,互联网就跟着“抖三抖”?
要理解这场事故有多严重,先得知道 Cloudflare 是什么。
简单来说,Cloudflare 是目前全球最大的互联网安全与 CDN(内容分发网络)提供商之一,它负责的事情主要包括:
● WAF、防火墙、DDoS 防护
● 验证访问者是否为人类(Bot Mitigation)
● CDN 加速
● 边缘网络与 Zero Trust 服务
● 网站流量代理与高级缓存
Cloudflare 官方称,全球 20% 的网站都在使用它的服务。换句话说:互联网的很大一部分流量,都要经过 Cloudflare 的基础设施,而它一旦出问题,成千上
万个网站就会同时“受牵连”。

正因如此,网络服务监测机构 NetBlocks 负责人 Alp Toker 才会说这次事故表示 Cloudflare 基础设施遭遇了“灾难级的中断”:“令人震惊的是,这几年为了
躲避 DDoS 攻击,互联网越来越多的服务都把 Cloudflare 作为前置层,这同时也让它成为了整个互联网的最大单点故障之一。”

真相曝光:一个“变得太大”的配置文件,引发连锁崩溃
故障爆发后,Cloudflare 很快进行了技术调查。
Cloudflare 官方发言人 Jackie Dutton 表示,这次宕机源于一个用于管理威胁流量的自动生成配置文件:“该文件的体积超出了预期,引发了处理流量的软件
系统崩溃,从而影响了 Cloudflare 多项核心服务。”
听起来是“小问题”?但在 Cloudflare 这种体量下,小问题可以瞬间变成“超级多米诺骨牌”。
在后续的技术复盘中,Cloudflare 解释这个“体积变大的文件”源于一次数据库权限变更:在一次 ClickHouse 权限的变更中,团队原本希望“让所有用户都
能准确看到自己有权访问的数据表元数据”。而这个本该是常规的权限完善,却引发了一场蝴蝶效应。
据了解,Cloudflare 的“机器人管理(Bot Management)”系统,需要依赖一份不断更新的“特征配置文件”。这份特征文件每几分钟更新一次,并自动同
步至整个网络,使其能够应对互联网流量的变化。但问题来了:由于底层 ClickHouse 查询行为的权限变更,导致生成的文件中出现了大量重复的“特征”行。
“该特征文件的大小随后翻倍,而这超出预期的特征文件被传播至构成我们网络的所有机器。这些设备上运行的网络流量路由软件会读取这份特征文件,确保
机器人管理系统能及时应对不断变化的威胁。但该软件对特征文件的大小设有限制,而此次文件大小翻倍后超出了这一限制,最终导致了软件故障。”
于是灾难链条启动:“过大的配置文件”→Cloudflare 处理威胁流量的模块开始崩溃→相关服务陆续降级→故障波及整个网络层→大量依赖 Cloudflare 的网站
出现连锁访问异常。
事后,Cloudflare CTO Dane Knecht 在 X 上公开道歉,并承认此次事件是他们的问题:
“我不会拐弯抹角:我知道,我们辜负了客户和整个互联网的信任。一个隐藏的 Bug 在我们进行一次例行配置变更后被触发,引发崩溃,最终导致我们的大量
网络与服务大面积降级。这不是攻击,是我们的失误。”
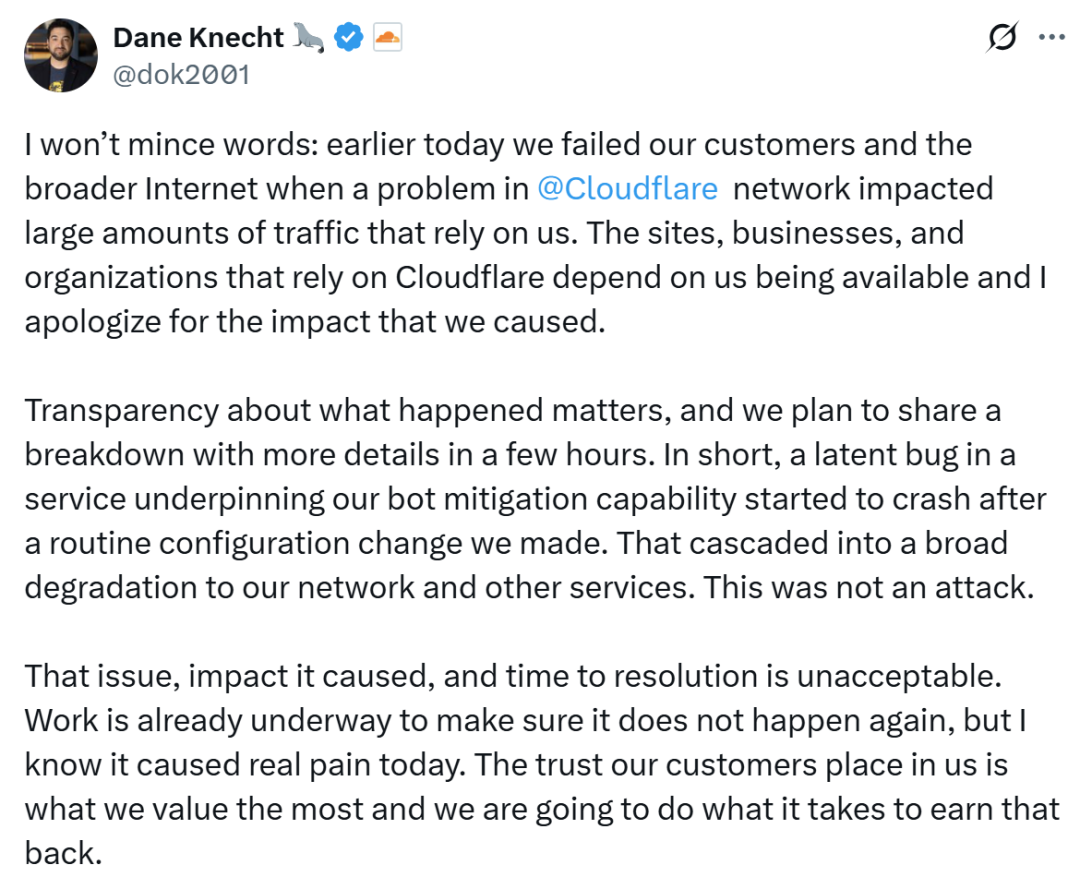
Dane Knecht 还强调,这是一次“不可接受的事故”。
故障持续三个多小时后,Cloudflare 于美东时间上午 9:42在状态页发布更新:“修复已实施,我们认为事件已经得到解决。但我们仍在持续监控,确保所有服
务完全恢复正常。”
虽然服务陆续恢复,但全球部分地区依然出现访问波动,一些企业的 API 业务也在恢复期遇到零星错误,这在大型服务“重启”过程中并不少见。值得注意的
是,受影响的还包括部分企业的内部服务与自动化流程,因此要真正恢复正常可能还需要花费一点时间。

一个月“崩”三次,互联网的脆弱性再次被暴露
回顾这短短一个月内,已经出现了至少三次“全球级事故”:
(1)AWS 大规模宕机,让 Fortnite、Alexa、Snapchat 以及数千网站全线掉线。
(2)随后微软 Azure 也遭遇类似问题,致使其大半的云生态服务受到影响,众多依赖 Azure 的企业服务也跟着遭殃。
(3)而本次 Cloudflare 的连锁崩溃,影响范围也波及全球。
对此,ESET 网络安全专家 Jake Moore 点出了关键问题:“最近频繁出现的大型宕机,再次凸显了我们对这些脆弱网络的高度依赖。”他指出,企业往往别无
选择,只能依赖 Cloudflare、微软、亚马逊,因为 “替代方案实在太少”。
也就是说:如今的互联网比我们想象的更加集中、同时也更加脆弱。而这些支撑着大半互联网的庞大中心,只要有一次“普通失误”,都可能瞬间变成一场全
球级灾难。
扫一扫,关注我们