
微博开源VibeThinker-1.5B大模型:15亿参数,挑战万亿参数AI巨头
写在前面
当整个AI行业都在追逐"更大即更强"的 scaling law 时,微博AI团队带来的VibeThinker-1.5B却用实实在在的数据告诉我们:小模型,同样可以拥有大智
慧。这个仅有15亿参数的"小个子",在AIME2025数学竞赛中斩获74.4分,超越了参数量400倍于它的DeepSeek R1;在代码生成任务上,它以51.1分的成绩
小幅领先Magistral Medium。更令人惊叹的是,这一切的实现成本不到8000美元。

一、最大的优点:成本极低但性能超强

(1)训练成本超级低:整个模型训练只花了7800美元,用了大约3900小时的H800显卡。相比动辄几十万上百万训练费的大模型(比如DeepSeek R1要
29.4万美元,MiniMax-M1要53.5万美元),它便宜了30-60倍。
(2)推理成本也低:因为模型小,可以轻松部署在手机、车载设备上,推理成本比大模型低20-70倍。
(3)性能却不输大模型:在AIME2025数学竞赛上拿到74.4分,超过了6710亿参数的DeepSeek R1(70.0分),和4560亿参数的MiniMax-M1(74.6分)差不
多。在代码生成任务LiveCodeBench v6上拿到51.1分,比 Magistral Medium(50.3分)还高一点。
二、颠覆性的技术思路:从“多样性”到“精准信号”
传统做法是让模型直接学标准答案,但他们搞了个新套路——先让模型学会“多想几种解法”,再从中挑出对的。具体分两步:
(1)第一步:多样性探索(他们叫“频谱阶段”)
不是直接教模型“唯一正确答案”,而是鼓励它针对一个问题生成多种解法。比如解一道数学题,模型可能会想出代数法、几何法、微积分法等不同思路。
他们用了个巧妙的办法:先把数学分成代数、几何、微积分、统计等几个小领域,在每个领域里训练一个“专项小能手”,然后把这几个小能手模型融合
成一个“全能模型”。这个融合后的模型解题思路特别广。
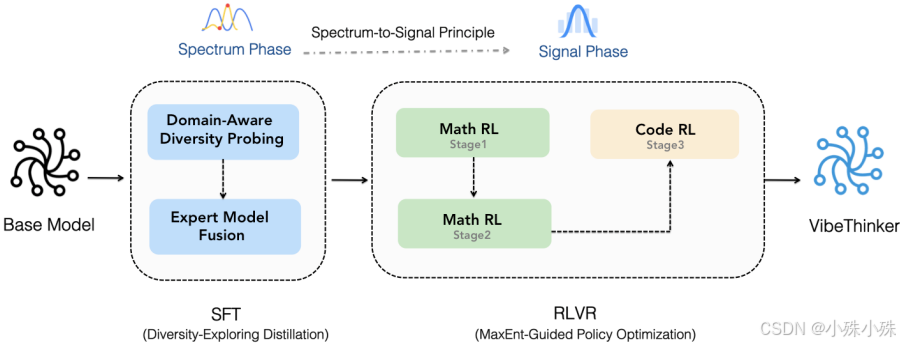
(2)第二步:信号放大(他们叫“信号阶段”)
有了多种解法后,用强化学习来“挑出对的”。他们开发了一个叫MGPO的智能算法,会自动找出模型“半懂不懂”的题目(就是正确率在50%左右的),
重点训练这些题,因为这时候学习效率最高。
这就像老师发现学生某些题型时对时错,就知道这是学生的“薄弱点”,应该重点讲解。
三、颠覆性结论:小模型也能有大智慧
这篇文章最颠覆的地方在于它证明了:模型能力不一定非要靠堆参数来实现!
(1)打破了“参数越多越聪明”的固有认知:之前大家都觉得推理能力必须靠大参数,但VibeThinker-1.5B用仅1.5B参数就达到了几百B参数模型的水平。
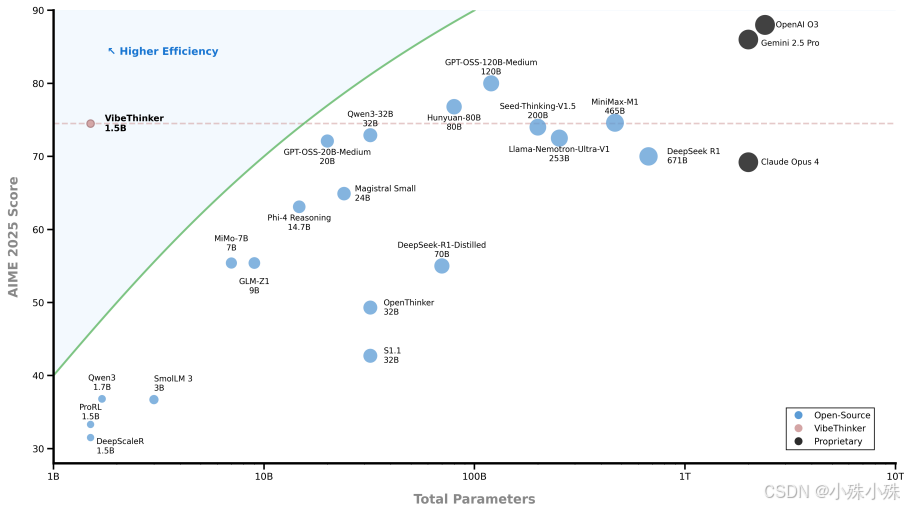
(2)降低了AI研究门槛:现在很多大学和小公司用不起大模型,如果小模型就能达到类似效果,更多人能参与前沿研究,加速AI发展。
四、还有提升空间
当然这个小模型也不是万能的:
(1)在专业知识测试(GPQA)上还不如大模型,差了20-40分,说明小模型在广泛知识存储上还是有局限。
(2)代码能力虽然不错,但相比数学推理稍弱,可能是因为基础模型原本就更侧重数学。
总之,这项研究就像证明了“小身材也能有大能量”,用创新的训练方法让小模型爆发出了超乎想象的推理能力,而且成本超级亲民,这对AI普及化来说
是个重大突破。
扫一扫,关注我们